criterion reportWe all know Haskell is a fast language, but is that all there is to it? Somewhat unsurprisingly, no. If you use the wrong algorithm, then no matter what you do, your code is going to run slow. In critical sections of code, a few milliseconds here and there can make all the difference. When you’re dealing with optimisations that are so fine grained you need to be confident that any changes you make are accurate and relevant, and you’re not just observing random chance.
criterion is the tool for the job. Another program by Bryan O’Sullivan, criterion allows you to benchmark segments of code to get accurate statistical information, including the mean, standard deviation, and more.
Essentially, you use criterion to add instrumentation to your existing code. In today’s example, I’ll use a fairly boring factorical implementation - though the code is not really the focus of todays topic.
fact :: Integ -> Integer
fact 1 = 1
fact n = n * fact (pred n)Good ol’ vanilla Haskell. Now, to instrument this, we simply write a little bit of code in IO ():
main :: IO ()
main = defaultMainWith
defaultConfig { cfgSamples = ljust 1000 }
(return ())
[ bench "fact 30" $ nf fact 30
, bench "fact 40" $ nf fact 40
]Now, running our application yields the following output:
warming up
estimating clock resolution...
mean is 3.024088 us (320001 iterations)
found 28199 outliers among 319999 samples (8.8%)
18604 (5.8%) low severe
9595 (3.0%) high severe
estimating cost of a clock call...
mean is 1.099025 us (28 iterations)
found 1 outliers among 28 samples (3.6%)
1 (3.6%) high severe
benchmarking fact 30
mean: 19.26216 us, lb 18.96798 us, ub 19.70640 us, ci 0.950
std dev: 5.765750 us, lb 4.274708 us, ub 7.555973 us, ci 0.950
found 31 outliers among 1000 samples (3.1%)
25 (2.5%) high severe
variance introduced by outliers: 99.783%
variance is severely inflated by outliers
benchmarking fact 40
mean: 33.72711 us, lb 32.38781 us, ub 35.19127 us, ci 0.950
std dev: 22.68707 us, lb 20.90844 us, ub 24.46324 us, ci 0.950
found 213 outliers among 1000 samples (21.3%)
204 (20.4%) high severe
variance introduced by outliers: 99.897%
variance is severely inflated by outliersUnfortunately, my laptop is really not a suitable benchmarking environment, as we can see! However, it’s nice to actually be clearly told that these are unreliable up front. criterion first attempts to measure clock resolution so it can provide accurate timing, and then we run our 2 benchmarks. We’re informed of the mean run time of a single sample (over 1000 samples), the upper and lower bounds, and the same for the standard deviation.
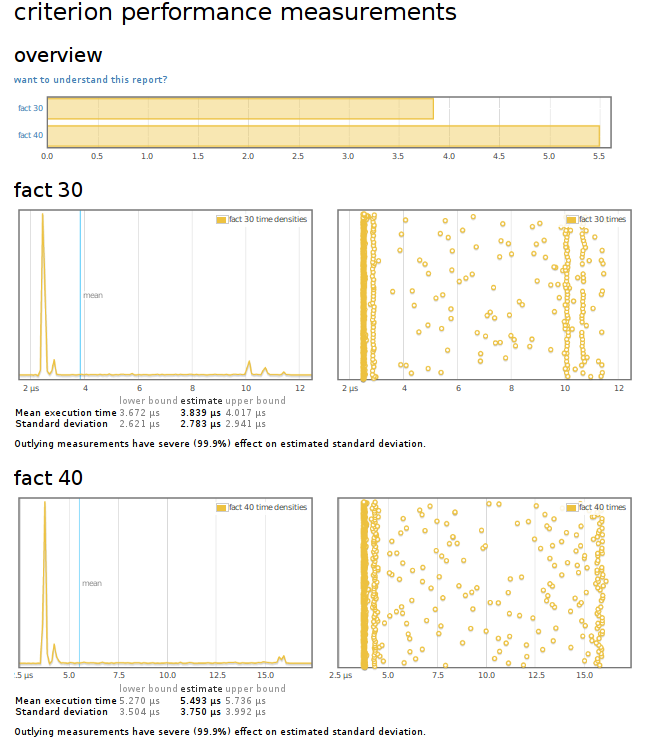
criterion can also output some lovely pretty graphs of these executions, and everyone likes pretty graphs:
This lets us visually scan the execution of our benchmark - allowing us to also visualize the distribution of timings.
criterion is a powerful tool, and one that you should definitely add to your arsenal if you looking to write production ready code. For more reading, have a look at Bryan’s initial announcement, along with some of the examples on GitHub.
You can contact me via email at ollie@ocharles.org.uk or tweet to me @acid2. I share almost all of my work at GitHub. This post is licensed under a Creative Commons Attribution-NonCommercial-NoDerivs 3.0 Unported License.








